谈到SQL优化,大家会异口同声的说建立索引,那么为什么建立了索引可以够提高效率?体现在哪?所有的查询都可以吗?什么样的查询才会提高效率?又有哪些注意事项呢?等等这一系列问题,下面让我们来一探究竟:
(一)SQLS如何访问没有建立索引的数据表
Heap译成汉语叫做“堆”,其本义暗含杂乱无章、无序的意思,前面提到数据值被写进数据页时,由于每一行记录之间并没有特定的排列顺序,所以行与行的顺序就是随机无序的,当然表中的数据页也就是无序的了,而表中所有数据页就形成了“堆”。可以说,一张没有索引的数据表,就像一个只有书柜而没有索引卡片柜的图书馆,书库里面塞满了一堆乱七八糟的图书。当读者对管理员提交查询请求后,管理员就一头钻进书库,对照查找内容从头开始一架一柜的逐本查找。运气好的话,在第一个书架的第一本书就找到了,运气不好的话,要到最后一个书架的最后一本书才找到。
SQLS在接到查询请求时,首先会分析sysindexes表中一个叫做索引标志符(INDID:IndexID)的字段的值,如果该值为0,表示这是一张数据表而不是索引表,SQLS就会使用sysindexes表的另一个字段FirstIAM值中找到该表的IAM页链,也就是所有数据页集合。
这就是对一个没有建立索引的数据表进行数据查找的方式,是不是很没效率?对于没有索引的表,对于一“堆”这样的记录,SQLS也只能这样做,而且更没劲的是,即使在第一行就找到了被查询的记录,SQLS仍然要从头到尾的将表扫描一次。这种查询称为“遍历”,又叫“全表扫描”。
可见没有建立索引的数据表照样可以运行,不过这种方法对于小规模的表来说没有什么太大的问题,但要查询海量的数据效率就太低了。
(二)SQLS如何访问建立了非聚集索引的数据表
非聚集索引可以建多个,具有B树结构,其叶级节点不包含数据页,只包含索引行。假定一个表中只有非聚集索引,则每个索引行包含了非聚集索引键值以及行定位符(ROWID,RID),他们指向具有该键值的数据行,每一个RID由文件ID、页编号和在页中行的编号组成。
当INDID的值在2至250之间时,意味着表中存在非聚集索引页。此时,SQLS调用ROOT字段的值指向非聚集索引B树的ROOT,在其中查找与被查询最相近的值,根据这个值找到在非叶级节点中的页号,然后顺藤摸瓜,在叶级节点相应的页面中找到该值的RID,最后根据这个RID在Heap中定位所在的页和行并返回到查询端。
例如:假定在Lastname上建立了非聚集索引,则执行Select*FromMemberWhereLastname=’Ota’时,查询过程是:
①SQLS查询INDID值为2;
②立即从根出发,在非叶级节点中定位最接近Ota的值“Martin”,并查到其位于叶级页面的第61页;
③仅在叶级页面的第61页的Martin下搜寻Ota的RID,其RID显示为N∶706∶4,表示Lastname字段中名为Ota的记录位于堆的第706页的第4行,N表示文件的ID值,与数据无关;
④根据上述信息,SQLS立刻在堆的第706页第4行将该记录“揪”出来并显示于前台(客户端)。视表的数据量大小,整个查询过程费时从百分之几毫秒到数毫秒不等。
在谈到索引基本概念的时候,我们就提到了这种方式:图书馆的前台有很多索引卡片柜,里面分了若干的类别,诸如按照书名笔画或拼音顺序、作者笔画或拼音顺序等,但有两点不同之处:
①索引卡片上记录了每本书摆放的具体位置——位于某柜某架的第几本——而不是“特殊编号”;
②书脊上并没有那个“特殊编号”。管理员在索引柜中查到所需图书的具体位置(RID)后,根据RID直接在书库中的具体位置将书提出来。
显然,这种查询方式效率很高,但资源占用极大,因为书库中书的位置随时在发生变化,必然要求管理员花费额外的精力和时间随时做好索引更新。
(三)SQLS如何访问建立聚集索引的数据表
在聚集索引中,数据所在的数据页是叶级,索引数据所在的索引页是非叶级。
查询原理和上述对非聚集索引的查询相似,但由于记录是按照聚集索引中索引键值进行排序,换句话说,聚集索引的索引键值也就是具体的数据页。
这就好比书库中的书就是按照书名的拼音在排序,而且也只按照这一种排序方式建立相应的索引卡片,于是查询起来要比上述只建立非聚集索引的方式要简单得多。仍以上面的查询为例:
假定在Lastname字段上建立了聚集索引,则执行Select*FromMemberWhereLastname=’Ota’时,查询过程是:
①SQLS查询INDID值为1,这是在系统中只建立了聚集索引的标志;
②立即从根出发,在非叶级节点中定位最接近Ota的值“Martin”,并查到其位于叶级页面的第120页;
③在位于叶级页面第120页的Martin下搜寻到Ota条目,而这一条目已是数据记录本身;
④将该记录返回客户端。
#p#分页标题#e#
这一次的效率比第二种方法更高,以致于看起来更美,然而它最大的优点也恰好是它最大的缺点——由于同一张表中同时只能按照一种顺序排列,所以在任何一种数据表中的聚集索引只能建立一个;并且建立聚集索引需要至少相当于源表120%的附加空间,以存放源表的副本和索引中间页。
难道鱼和熊掌就不能兼顾了吗?办法是有的。
(四)SQLS如何访问既有聚集索引、又有非聚集索引的数据表
如果我们在建立非聚集索引之前先建立了聚集索引的话,那么非聚集索引就可以使用聚集索引的关键字进行检索。就像在图书馆中,前台卡片柜中可以有不同类别的图书索引卡,然而每张卡片上都载明了那个特殊编号——并不是书籍存放的具体位置。这样在最大程度上既照顾了数据检索的快捷性,又使索引的日常维护变得更加可行,这是最为科学的检索方法。
也就是说,在只建立了非聚集索引的情况下,每个叶级节点指明了记录的行定位符(RID);而在既有聚集索引又有非聚集索引的情况下,每个叶级节点所指向的是该聚集索引的索引键值,即数据记录本身。
假设聚集索引建立在Lastname上,而非聚集索引建立在Firstname上,当执行Select*FromMemberWhereFirstname=’Mike’时,查询过程是:
①SQLS查询INDID值为2;
②立即从根出发,在Firstname的非聚集索引的非叶级节点中定位最接近Mike的值“Jose”条目;
③从Jose条目下的叶级页面中查到Mike逻辑位置——不是RID而是聚集索引的指针;
④根据这一指针所指示位置,直接进入位于Lastname的聚集索引中的叶级页面中到达Mike数据记录本身;
⑤将该记录返回客户端。
这就完全和我们在“索引的基本概念”中讲到的现实场景完全一样了,当数据发生更新的时候,SQLS只负责对聚集索引的键值加以维护,而不必考虑非聚集索引。只要我们在ID类的字段上建立聚集索引,而在其它经常需要查询的字段上建立非聚集索引,通过这种科学的、有针对性的在一张表上分别建立聚集索引和非聚集索引的方法,我们既享受了索引带来的灵活与快捷,又相对避免了维护索引所导致的大量的额外资源消耗。
为什么能够提高查询速度?
索引就是通过事先排好序,从而在查找时可以应用二分查找等高效率的算法。
一般的顺序查找,复杂度为O(n),而二分查找复杂度为O(log2n)。当n很大时,二者的效率相差及其悬殊。
举个例子:
表中有一百万条数据,需要在其中寻找一条特定id的数据。如果顺序查找,平均需要查找50万条数据。而用二分法,至多不超过20次就能找到。二者的效率差了2.5万倍!
在一个或者一些字段需要频繁用作查询条件,并且表数据较多的时候,创建索引会明显提高查询速度,因为可由全表扫描改成索引扫描。
(无索引时全表扫描也就是要逐条扫描全部记录,直到找完符合条件的,索引扫描可以直接定位)
不管数据表有无索引,首先在SGA的数据缓冲区中查找所需要的数据,如果数据缓冲区中没有需要的数据时,服务器进程才去读磁盘。
1、无索引,直接去读表数据存放的磁盘块,读到数据缓冲区中再查找需要的数据。
2、有索引,先读入索引表,通过索引表直接找到所需数据的物理地址,并把数据读入数据缓冲区中。
索引有什么副作用吗?
(1)索引是有大量数据的时候才建立的,没有大量数据反而会浪费时间,因为索引是使用二叉树建立.
#p#分页标题#e#
(2)当一个系统查询比较频繁,而新建,修改等操作比较少时,可以创建索引,这样查询的速度会比以前快很多,同时也带来弊端,就是新建或修改等操作时,比没有索引或没有建立覆盖索引时的要慢。
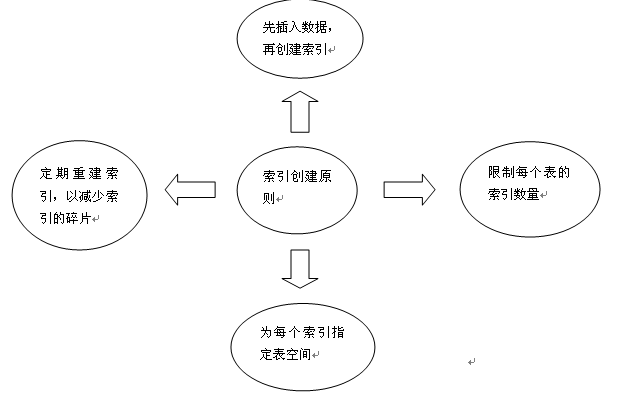
(3)索引并不是越多越好,太多索引会占用很多的索引表空间,甚至比存储一条记录更多。
对于需要频繁新增记录的表,最好不要创建索引,没有索引的表,执行insert、append都很快,有了索引以后,会多一个维护索引的操作,一些大表可能导致insert速度非常慢。
小编结语:
索引是表的一个概念部分,用来提高检索数据的效率,Oracle使用了一个复杂的自平衡B-tree结构.通常,通过索引查询数据比全表扫描要快.当ORACLE找出执行查询和Update语句的最佳路径时,ORACLE优化器将使用索引.同样在联结多个表时使用索引也可以提高效率.另一个使用索引的好处是,它提供了主键(primarykey)的唯一性验证.那些LONG或LONGRAW数据类型,你可以索引几乎所有的列.通常,在大型表中使用索引特别有效.当然,你也会发现,在扫描小表时,使用索引同样能提高效率.虽然使用索引能得到查询效率的提高,但是我们也必须注意到它的代价.索引需要空间来存储,也需要定期维护,每当有记录在表中增减或索引列被修改时,索引本身也会被修改.这意味着每条记录的INSERT,DELETE,UPDATE将为此多付出4,5次的磁盘I/O.因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢。定期的重构索引是有必要的。
