How to master a skillJump into the middle of things, get your hands dirty, fall flat on your face, and then reach for the stars.—— Ben Stein
语言选择一般而言, 咨询公司为贸易银行搭建统计评分卡模子,回收的语言大多是SAS,这是因为SAS语言背后,有SAS公司 (SAS Institute)提供很完备的产物方案和售后处事。对付措施安详性和不变性要求较高的银行, 自然会将SAS作为第推荐方案。
而对付小我私家用户, 要想搭建一个评分卡模子,会更多思量搭建开拓情况的容易度、统计包或库的获取的容易水平(accessablity)、代码气势气魄等。开源易懂的R语言自然会成为小我私家用户小试牛刀的推荐。
数据筹备我们将会利用在信用评级建模中非经常用的德国信贷数据(German credit dataset)作为建模的数据集,详细的数据下载源请见文末的引用。德国信贷数据共有1000条数据,每条数据20个特征。这些特征包罗AccountBalance(Checking账户余额)、Duration (Duration of Credit in month 借钱期限)、Paymentstatus(还款记录)等。 个中较量难以领略的指标是Instalmentpercent,其代表着 Installment rate in percentage of disposable income (分期付款占可支配收入的百分比)。
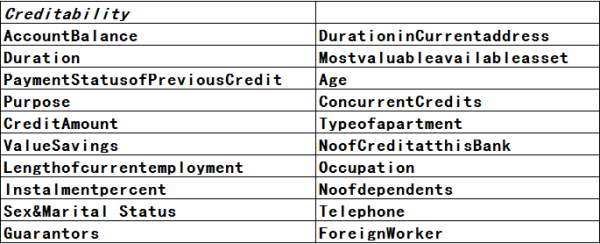
模子指标汇总
而数据会合需要预测的指标是(response variable)个中的Creditability变量, 个中 1代表好客户(会还本付息),0则是代表坏客户。
以下是载入数据及练习集分别部门的R代码:library(caret)train1 <-createDataPartition(y=german_credit$Creditability,p=0.75,list=FALSE)train <- german_credit[train1, ]test <- german_credit[-train1, ]建模进程凡是来讲,建构一个信用评分卡,要如下几个步调:
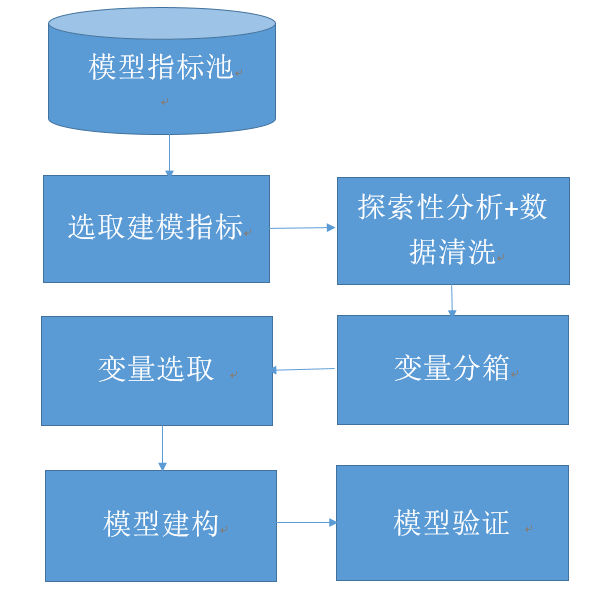
在本文,因我们利用的数据是现有的数据集,所以不必举办指标选取和一些数据清洗的进程(如缺失值插补)。接下来,我们会按照以上步调,一步步构建本身的评分卡模子。
摸索性数据阐明在成立模子之前,我们一般会对现有的数据举办 摸索性数据阐明(Exploratory Data Analysis) 。 EDA是指对已有的数据(出格是观测或调查得来的原始数据)在只管少的先验假定下举办摸索。常用的摸索性数据阐明要领有:直方图、散点图和箱线图等。
首先让我们用直方图看一下Duration的漫衍环境:require(caret)data(GermanCredit)ggplot(GermanCredit, aes(x = duration,y = ..count..,)) + geom_histogram(fill = “blue”, colour = “grey60”, size = 0.2, alpha = 0.2,binwidth = 5)
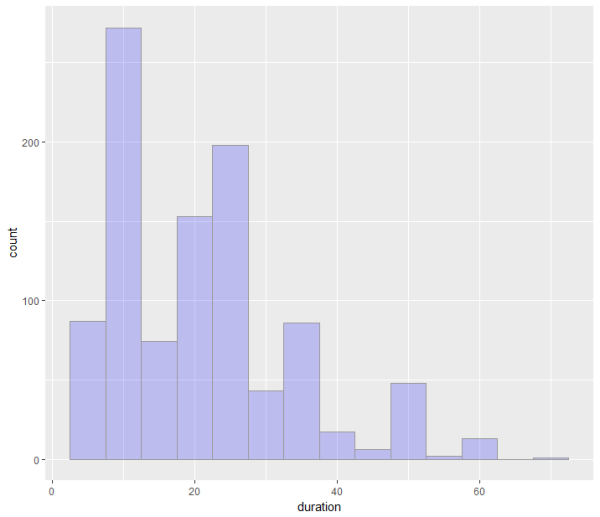
从上面的频率漫衍直方图中, 可以看出German Credit Data中的贷款期限,多半在40个月以内。 而申请人数最多的期限,则是6-10个月的短期贷款。
让我们再看一下CreditAmount的漫衍环境ggplot(GermanCredit, aes(x = Amount,y = ..count..,)) + geom_histogram(fill = “blue”, colour = “grey60”, size = 0.2, alpha = 0.2,binwidth = 1000)
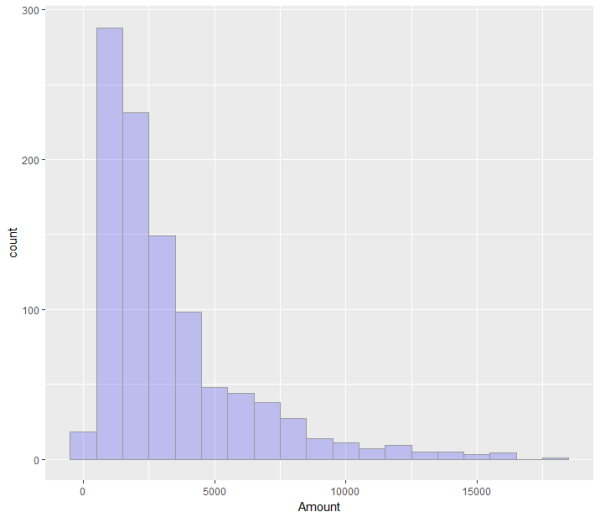
就贷款金额而言,大大都申请人将其节制在5000马克之内。个中以申请1000-3000马克的小额贷款最多。
最后再来看一下违约人数在总人数的占比,也就是Creditability这部门的数据。ggplot(GermanCredit, aes(x =Creditability,y = ..count..,)) + geom_histogram(fill = “blue”, colour = “grey60″ , alpha = 0.2,stat=”count”)
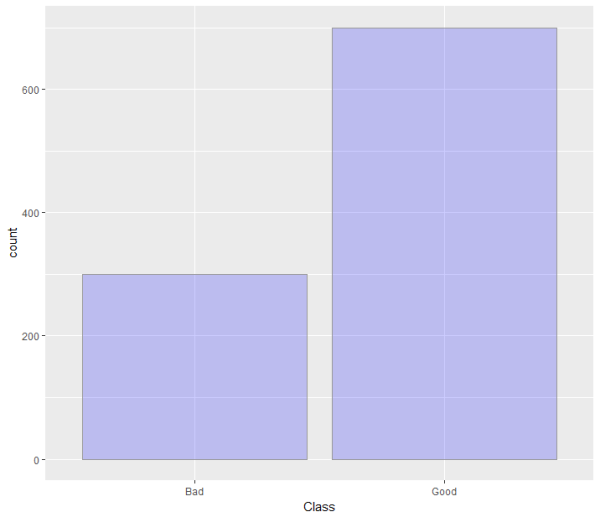
从图中可以看出,数据会合30%的申请人被分别为违约的坏用户。而剩下70%的人则是会还本付息的好用户。
变量分箱在评分卡建模中,变量分箱(binning)是对持续变量离散化(discretization)的一种称号。要将logistic模子转换为尺度评分卡的形式,这一环节是必需完成的。信用评分卡开拓中一般有常用的等距分段、等深分段、最优分段。
个中等距分段(Equval length intervals)是指分段的区间是一致的,好近年数以十年作为一个分段;等深分段(Equal frequency intervals)是先确定分段数量,然后令每个分段中数据数量大抵相等;最优分段(Optimal Binning)又叫监视离散化(supervised discretizaion),利用递归分别(Recursive Partitioning)将持续变量分为分段,背后是一种基于条件揣度查找较佳分组的算法(Conditional Inference Tree)。
我们将利用最优分段对付数据会合的Duration、age和CreditAmount举办分类。首先,需要在R中安装smbinning包。对三者举办最优分箱:library(smbinning)Durationresult=smbinning(df=train,y=”Creditability”,x=”Duration”,p=0.05)CreditAmountresult=smbinning(df=train2,y=”Creditability”,x=”CreditAmount”,p=0.05) Ageresult=smbinning(df=train2,y=”Creditability”,x=”Age”,p=0.05)
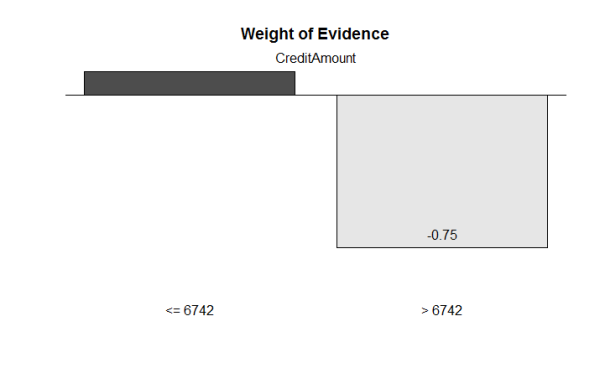
查察分箱后变量各箱的WoE变革:smbinning.plot(CreditAmountresult,option=”WoE”,sub=”CreditAmount”)
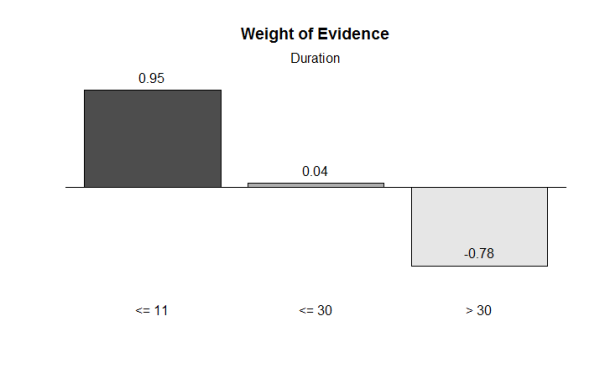
smbinning.plot(Durationresult,option=”WoE”,sub=”Duration”)
smbinning.plot(Ageresult,option=”WoE”,sub=”Age”)#p#分页标题#e#
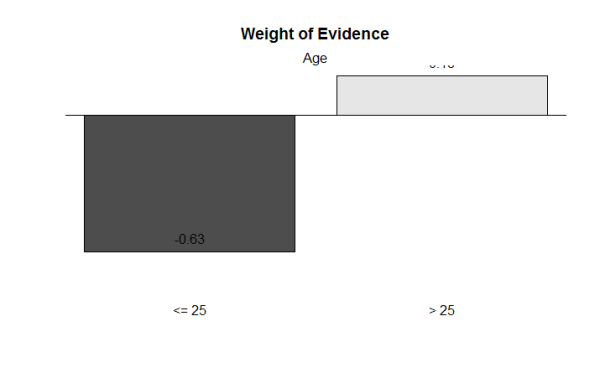
通过最优分段, 我们将CreditAmount贷款数额这一持续变量分为了[0,6742]和(6742, +∞]两段。Duration借钱期限变量被分为了[0,11]、(11,30] 和 (30, +∞]三段。而Age申请人年数被分为[0, 25]和(25, +∞]两段。变量的分段都对应差别较大WoE值,说明分段区分结果较好,且无违背Business Sense的现象呈现,可以接管最优分段提供的分箱功效。
接待插手本站果真乐趣群贸易智能与数据阐明群乐趣范畴包罗各类让数据发生代价的步伐,实际应用案例分享与接头,阐明东西,ETL东西,数据客栈,数据挖掘东西,报表系统等全方位常识QQ群:81035754
