Stats 485 paper
统计论文作业代写 Pick one of the two options below. For data, and some additional instructions, refer to the accompanying Technical Appendices assignment.
Pick one of the two options below. For data, and some additional instructions, refer to the accompanying Technical Appendices assignment.
Option A: GMP and population size
U.S. statistical agencies divide the country into several hundred metropolitan statistical areas or MSAs; these are larger than commuting zones. The U.S. Bureau of Economic Analysis estimates these MSAs’ contributions to the country’s gross domestic product, yielding gross metropolitan products (GMPs). Some academicians have claimed that these GMPs follow “supra-linear power law scaling”: if Y is the GMP and N is the population size of the metropolitan area, then
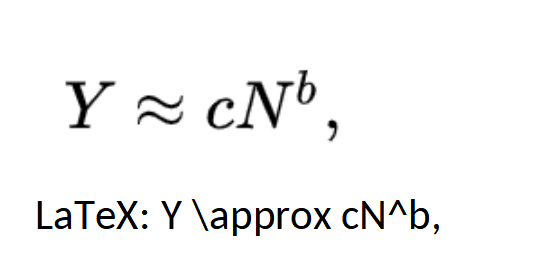
for some c>0 and b>1. Their theory is that this pattern reflects greater economic efficiencies that are available in larger local economies. According to this theory, if we were to encourage people living in less densely populated areas to move to more concentrated areas, economic productivity would improve.
Competing theories explain larger metropolitan areas’ proportionately greater GMPs as a matter of the types of economic activity that tend to concentrate in cities. For example, New York, Chicago and San Francisco all have large concentrations of financial firms, but few less-dense metropolitan areas do; perhaps the greater productivity of these and other large cities is a function of financial firms having chosen to locate in large cities.
In this assignment you’ll assess the power-law scaling proposal, 统计论文作业代写
Develop alternate models predicting GMP as a linear but not supra-linear function of population size, as well as of other variables describing the nature of its local economy; compare the models’ fit to the data using a loss function of your choice, and offer an assessment of the proposition that among comparably simple models of GMP, the power-law scaling model best summarizes the economic productivity of a locale.
If you want to review the academic paper on which this exercise is based, it’s the paper by Bettencourt et al in the readings folder; here (Links to an external site.) is the abstract.
And here’s a video of the senior author of that paper, Geoffrey West, giving a TED talk about it and related topics (in front of, for some reason, a piano and a rainforest scene): youtube.com/watch?v=XyCY6mjWOPc
Data. 统计论文作业代写
Data for this project consist of a table of records describing MSAs in 2006: from the U.S. Census Bureau, estimates of population size; from the U.S. Bureau of Economic Analysis, estimates of GMP and of the shares of GMP in each of four sectors of economic activity (finance, finance; professional and technical services, prof.tech; information, communication and technology, or ict; management of firms and enterprises,management).
Assignment.
Present a report explaining your investigation of whether a supra-linear power law characterizes the GMP-population regression for these data, and whether variation in GMP can be explained just as well in terms of shares of economic activity in different sectors. The report should consider multiple models for GMP.
Paper structure.
Your paper should have 4 sections: Introduction, Methodology, Results, Discussion. Aim for a length of 6-8 double-spaced pages, not including the appendix. It should be submitted in a PDF file containing both the paper and the “knitted” version of your appendix.
Intended audience. 统计论文作业代写
Graduate students in urban planning, who are familiar with this argument and curious about other alternative models or explanations for local economic performance. Or, the head of a nonprofit organization advising displaced refugees on where to relocate their families within the United States, one of the decisions being whether to advise refugees that they and their children will face better economic odds in more or less densely populated regions.
Sections of the paper.
Your paper should follow the same introduction-methodology-results-discussion organization as last time. Suggestions on contents of the specific sections:
Introduction:
Motivate the analyses you’ll be presenting in the paper, indicating what data you’ll use and what question or questions you’ll be using the data to shed light on. Describe in broad terms the “supra-linear” model and alternatives your paper will consider, particularly if doing so enables you to present your research questions more easily or clearly. Indicate what’s interesting about the particular alternative to the supra-linear model that you chose to investigate.
Methodology: 统计论文作业代写
Indicate how you encoded supra-linear power law scaling into a statistical model, as well as the statistical models with which you represented your alternative model. Note any major methodological decisions you made (e.g., variable transformations). Describe how you evaluate the fit of your models. This section describes your decisions, but it shouldn’t “teach” the reader the methods. Highlight aspects likely to impress or otherwise interest your intended audience.
Results:
What do your estimated models suggest about the plausibility of the supra-linear power scaling model? In terms of model fit, how do alternative models compare to the power scaling model or to each other? Can you draw any conclusions on what is a good model for these data? If you include tables or figures, they should be clearly labeled, and should be accompanied by a caption that’s sufficiently informative that a busy reader can understand the figure or table while only skimming the rest of the text. Patterns in the table or figure should also be concisely described in the text. If you’re reporting hypothesis tests, emphasize whether the findings supported or did not support research hypotheses, not the p-value or whether the null was rejected. Estimates and standard errors should be reported to 2 or 3 significant digits.
Discussion: 统计论文作业代写
Review the substantive questions you investigated and summarize what you learned by fitting and evaluating your models. What did you learn about the power-law model and about the other explanatory variables you decided to look at? (If you find yourself at a loss about how to organize this section, consider trying out the template suggested in the prompt for Unit 1 Paper, Version 2.)
Overall tips:
Do not include R code within the body of your paper. Your audience is not expected to know R, and shouldn’t have to learn any R in order to take in your findings. Do pick and choose what analyses to describe so as to tell the story of your investigation, making it easy for the reader to follow what you did. Do not set out to justify your methods; do indicate what they assume and what they mean. Don’t use block quotes; do give specific references where appropriate, following a consistent citation style.
Option B: Possible gender differences in the overconfidence study 统计论文作业代写
(Based on the 2016 article by Ehrlinger et al, discussed in class in mtg2d and subsequent meetings. It’s available in Readings on Perusall.)
The paper “Understanding overconfidence: Theories of intelligence, preferential attention, and distorted self-assessment,” by Ehrlinger, Mitchum and Dweck (2016, J. Experimental Social Psychology), presents empirical findings from three lab studies exploring connections between overconfidence, attention allocation and how we think about intelligence. In this paper assignment you’ll provide an independent analysis of data from their study 3. (You can find the paper in the readings subfolder of the course Library on Perusall, and the data for study 3 at http://dept.stat.lsa.umich.edu/~bbh/s485/data/emdstudy3-small-nogender.csv and http://dept.stat.lsa.umich.edu/~bbh/s485/data/emdstudy3-small.csv .)
Like Study 1, 统计论文作业代写
Discussed in class, Ehrlinger et al’s study 3 enrolled undergraduate college students; had them complete a questionnaire, from which they could be assigned a “theory of intelligence” score; had them take a short GRE-like examination; and ultimately asked them to estimate their performance on that short exam. In contrast to Study 1, Study 3 had students review the questions before estimating performance on them, and it randomly assigned participants to either of two conditions for this review: one condition heightened the participant’s attention on easier questions on the test, while the other directed her or his attention toward the test’s harder questions.
Study 3’s main finding was that having one’s attention directed to harder questions during review tended to reduce the participant’s overestimate of his or her score. In Ehrlinger et al’s interpretation, that is, it reduced overconfidence. Study 3 and its findings are described in detail in Section 5 of the article.
Note 2 of the article indicates that within each of the 3 studies, 统计论文作业代写
Similar relationships between overconfidence and theory-of-intelligence variables were found in male and in female participants. However, supplemental material suggests that this was somewhat less clear for study 3 — perhaps the overconfidence variable’s regression on theory of intelligence plus experimental condition was different for men and for women. In this assignment you’ll develop your own model of this regression relationship, and from the perspective of this model offer a principled, empirical assessment of whether the regression of overconfidence on theory of intelligence and experimental condition is different for women versus for men.
Data.
Data for this project consist of observations on men and women participants in Ehrlinger et al’s Study 3: intel_theory, a measurement constructed from questionnaire responses, with lower scores suggesting that the participant held an “entity theory” of intelligence whereas higher scores suggest “incremental theories”; gender, either M or W for each study participant; attn_to, whether the participant was randomly assigned to have her/his attention directed toward easy or hard problems, during post-exam review; ActPerc, the participant’s actual percentile score on the test; and EstPerc, the estimated percentile score the participant gave after taking the test and reviewing the test items.
Assignment. 统计论文作业代写
Operationalize “overconfidence” either in terms of the EstPerc variable alone, or as a function of EstPerc and other variables. Then model your overconfidence variable’s regression on intel_theory and experimental condition, attn_to, in two ways.
First, model
E(Y | intel_theory, attn_to),
where Y is your overconfidence variable, without attention to gender. Fit your model and then use graphical techniques look for unexplained variation that might potentially be explained by gender, or perhaps gender in combination with other variables (see appendix assignment). If you succeed in finding something interesting or suggestive, consider whether you can present a visual display illustrating this phenomenon avoids specialized technical notions, e.g. “residual,” and that the target audience can readily understand. If so, consider presenting that visualization in your paper; otherwise, your paper can refer can cross-reference the parts of the appendix where the visualizations that you constructed appear. Also explore whether men and women differed on the independent variables intel_theory and attn_to, noting differences that strike you as sufficiently large that they may bear on assessments of model fit by gender.
Second, fit a variation of your first model aiming to capture 统计论文作业代写
E(Y | intel_theory, attn_to, gender) .
That is, this model should permit gender as well as intelligence theory and experimental condition to make independent contributions to the regression function. Select and fit a model capable of capturing any gender differences suggested by the graphs you created earlier.
Also calculate in-sample loss for the versions of the first and second models that you ultimately select. If you can, formulate and test a statistical hypothesis expressing the distinction between these models. If you take this route, be sure to explain and evaluate your test’s assumptions. Either way, provide your assessment of whether in this sample the relationship of overconfidence to intelligence theory and experimental condition differed for men and women.
Paper structure. 统计论文作业代写
Your paper should have 4 sections: Introduction, Methodology, Results, Discussion. Aim for a length of 6-8 double-spaced pages, not including the appendix. It should be submitted in a PDF file containing both the paper and the “knitted” version of your appendix.
Intended audience.
Undergraduate or graduate students in psychology who take an interest in overconfidence phenomena discussed in Ehrlinger et al’s introduction. Alternatively, high school teachers interested to identify and address patterns of over- or under-confidence in their students.
Sections of the paper.
Your paper should follow the same introduction-methodology-results-discussion organization as last time.
Overall tips: Do not include R code within the body of your paper. Your audience is not expected to know R, and shouldn’t have to learn any R in order to take in your findings. Do pick and choose what analyses to describe so as to tell the story of your investigation, making it easy for the reader to follow what you did. Do not set out to justify your methods; do indicate what they assume and what they mean. Don’t use block quotes; do give specific references where appropriate, following a consistent citation style.
Rubric 统计论文作业代写
Stats 485 paper rubric template_
| Stats 485 paper rubric template_ | ||||
| Criteria | Ratings | Pts | ||
| This criterion is linked to a Learning OutcomeIntroduction
Introduces topic, research questions the paper will address. Builds interest, perhaps by foreshadowing or describing in general terms key methods or results. |
|
1 pts | ||
| This criterion is linked to a Learning OutcomeData
Describes the data, including samples, sources and variables used in the analysis. |
|
1 pts | ||
This criterion is linked to a Learning OutcomeMethods of analysis are given in suitable detail 统计论文作业代写Models are introduced or explained in ways that make clear their major assumptions, as well as and their role in addressing research questions. |
|
1 pts | ||
| This criterion is linked to a Learning OutcomeMethods: Additional paper-specific assessment
(We’ll also evaluate each paper on its description of selected concepts or procedures arising in the prompt.) |
|
1 pts | ||
| This criterion is linked to a Learning OutcomeResults: paper-specific assessment
(We’ll evaluate each paper on its presentation of selected results needed to address research questions.) |
|
1 pts | ||
This criterion is linked to a Learning OutcomeResults: clarity of reporting 统计论文作业代写Results are presented both in words and with at least one accompanying table or figure. Any tables or figures are clearly labeled, organized in a manner that facilitates comprehension by the reader, and convey suitable precision. They’re described in the body of the paper; in addition, they are accompanied by a sufficiently informative caption that a hasty reader can understand the paper while only skimming the text. |
|
1 pts | ||
| This criterion is linked to a Learning OutcomeDiscussion
Reviews or highlights findings salient to research topic. Addresses strengths and limitations of data and/or statistical methods for drawing conclusions about these subjects. |
|
1 pts | ||
This criterion is linked to a Learning OutcomeOrganization of content 统计论文作业代写Material the reader needs (in order to follow the report) is appropriately placed in introduction, methods, results and discussion sections of the paper; these sections are internally structured in a manner that helps the reader make sense of the paper. |
|
1 pts | ||
| This criterion is linked to a Learning OutcomeUse of technical and specialized terms
Terms specific to the subject matter and/or statistical methods, particularly those that will be new to, or used in ways unfamilar to the intended audience, are introduced when used. As appropriate, the paper introduces shorthand labels for variables/features or models constructed in the course of the analysis. The introduction may consist in a definition, an explanation of how the term is to be understood within your paper, and/or a citation, as is appropriate for clarity to the intended audience. |
|
1 pts | ||
| This criterion is linked to a Learning OutcomeAdditional paper-specific criteria
(There may be additional rubric criteria specific to the paper, grounded in the paper prompt. We may omit criteria that appear above, and/or increase others’ point values.) |
|
1 pts | ||
| Total Points: 10 | ||||

更多代写:cs Different tests代考 托福保分 英国exam代考网课 Essay润色价格 academic papers代写 计算方法统计代写
