explain指令的应用方法:
explain sql句子
explain回到結果的字段名表述:
Id 用以表明查看中实行select子句或实际操作表的次序
3种状况:
A. id同样实行次序由上升下
例如:
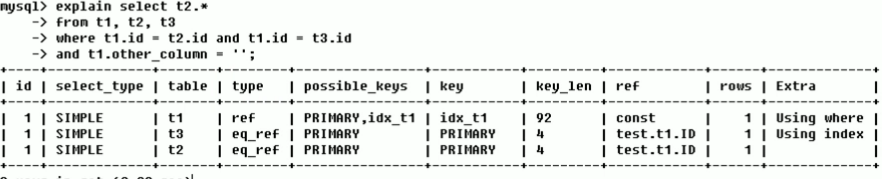
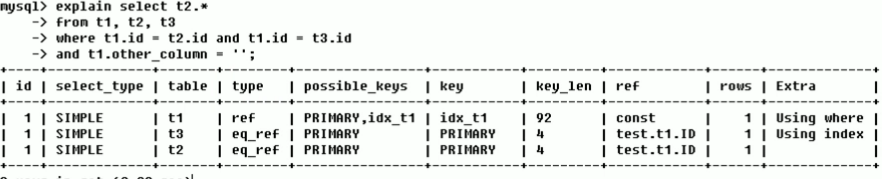
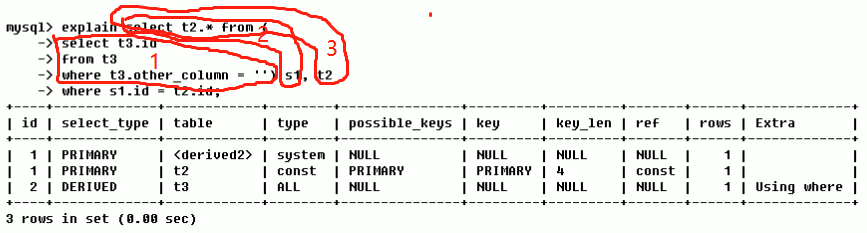
看第一列和第三列:Id都是1,因此 实行的次序是先载入t1 , 随后 t3,最终t2
B.Id不一样:如果是子查询,id的编号会增长,id值也大优先越高,越先强制执行
例如:
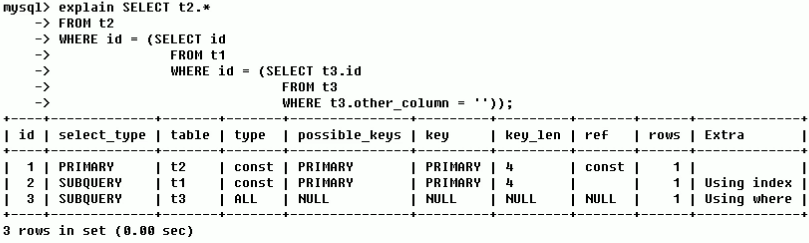
看第一列和第三列:先实行查t3表的子查询,再实行t1子查询,最终查t2查看
C.Id同样不一样都存有
例如:
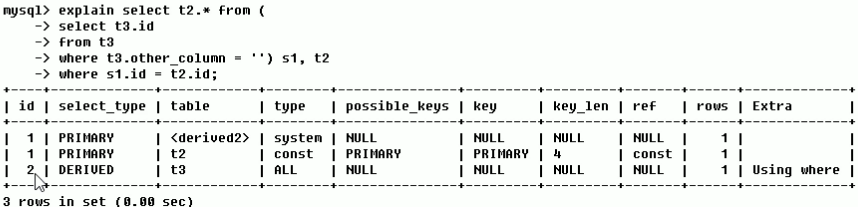
看第一列和第三列:最先会实行id大的sql,随后id同样的则从上向下次序实行。
derived是衍化表的意思,也就是mysql把 select t3.id from t3 where xxx 这句话的实行結果解决变成一个虚似的表,这类把一个查看的結果临时性存为一个表便是衍化表。
derived2中的2是id,表明这张衍化表有id为2的句子转化成的衍化表,也就是表s1。
因此 上边的实行次序是:
Select_type 查看种类
有6类:
Simple 简易查看,即不包含子查询和union的查看
Primary 查看中假如包括子查询或union查看,最表层查看会标识为primary
Subquery 表明select或where中包括子查询
Derived 在from中包括的子查询会被标识为derived。Mysql会递归实行这种子查询,把头查看的結果放到临时表中
Union 若第二个select出現在union以后,则被标识为union;若union包括在from中的子查询,则表层select会标识为derived
Union result 从union表获得結果的select
Table 表明这一行的数据信息是有关哪张表的
Type 浏览种类
有8类,特性从好到坏先后是
System > const > eq_ref > ref > range > index >all
要确保查看最少做到range等级,最好是能做到ref等级。
System 表仅有一条纪录(具体中基础不会有这一状况)
Const 当标准查看是对主键或是唯一键开展精准查看(=);比如 select * from t1 where id=1,mysql会将这一条纪录做为变量定义。
Eq_ref 唯一性数据库索引扫描仪。当应用唯一键为标准查看时便是eq_ref。
比如select * from user where userName = ‘abc’
Ref 相对性应eq_ref,当应用一般数据库索引做为标准开展精准查看时便是ref, 一般数据库索引能够有反复的字段名值。
比如: select * from employee where name = ‘zbp’ 这条句子并不是eq_ref只是ref,由于name并不是唯一索引只是个一般数据库索引,姓名容许同名。
Eq_ref 总是回到一条纪录,而ref能够回到好几条纪录
Range 对加上了数据库索引的字段名开展范畴搜索
如 in/bettween/</>
Index index表明应用了覆盖索引。Index和all相同之处是都是会对所有的叶子节点开展解析xml。差别是index解析xml的是没有行数据信息的叶子节点(只解析xml数据库索引值),all是解析xml带有行数据信息的叶子节点,换句话说index解析xml的频次和all一样,可是每一次解析xml(载入)的信息量比all小许多。因此 index会比All快好多好多好多好多。
比如 select id from t1;
All 全表扫描仪
比如 select * from t1;
Possible_key 表明很有可能采用的数据库索引
Key 是具体采用的数据库索引;只需key字段名有值,那毫无疑问就用到了数据库索引
假如key这一列入null,则沒有应用数据库索引;
Key_len 数据库索引中应用的字节
根据该字段名能够分辨我的联合索引中的字段名是所有字段名都应用到数据库索引還是仅有一部分应用了。
Ref 表明什么列或是变量定义被做为被查找值去开展搜索
比如:

只看ref字段名这儿表明,t2的col1及其变量定义 ‘ac’ 被做为要搜索的值开展查找。
Rows 大概估计出查看的情况下要扫描仪是多少行纪录
Extra 关键的附加信息内容
Using filesort 应用了文件排序
mysql中没法运用数据库索引进行的排列,又称为“文件排序”。出現这类状况很危险,特性不太好。
(PS 文件排序并不是在文档中开展排列只是在运行内存中开展排列,你用手指想一想怎么可能在文档中开展排列嘛)
例如:我建了联合索引 index(col1, col2, col3)
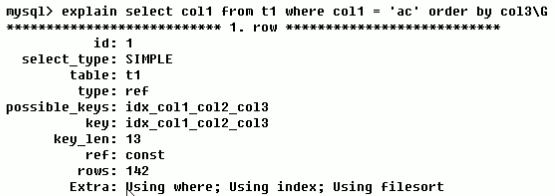
这条句子的where应用到数据库索引,可是order by排列的情况下沒有采用数据库索引的排列,因此 用了文件排序。代表着mysql要再次对結果集在运行内存中(sort_buffer 排列缓冲区域)排列。
Using temporary: 应用了临时表储存正中间結果
当mysql对查看的結果排列或排序时因为内存不够以储放要排列的內容,很有可能会內部建立临时表。出現了这一比using filesort 还惨,由于內部建立临时表代表着会造成附加的IO。
例如:
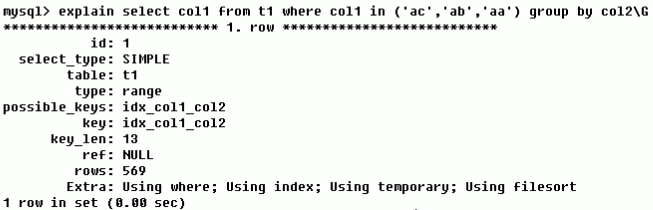
从 Using temporary 和 Using filesort 这一事例表明,即便where采用了数据库索引,但假如排列没用到数据库索引,特性也不太好。
Using index 应用了覆盖索引
出現这一,特性会非常好
假如另外出現using where ,说明数据库索引用于实行where标准搜索
要是没有出現using where,说明select查的是数据库索引列,可是沒有实行where搜索。
比如:

它是另外出現 using index 和 using where

只出現了 using index
Using where 应用了标准查看
也有别的的可是工作上非常少见。
最重要的還是 using filesort、using index 和 using temporary
Using join buffer 应用联接缓存文件
当开展3个及之上的表的联查的时候会出現 Using join buffer。出現这个是一切正常状况,联查的表多了以后mysql毫无疑问要对每一次联立的表做一个缓存文件再联立过一个表。只需应用3个表之上的多表联查就难以避免出現这一。
跟招聘者聊的情况下,实际上最重要的是 id/type/key/rows/extra 这5个最重要。
=============================================
下面举好多个sql优化实例:
1.有一个文章内容表,仅有id主键,别的字段名沒有创建数据库索引
现规定查看 category_id 为1 且 comments 超过1 的状况下,按views排列的数据信息
Select * article where category_id = 1 and comments > 1 order by views
Explain 剖析以下:

沒有应用数据库索引,并且排列是一个文件排序。
提升1: 建立联合索引 index idx_article_ccv (category_id, comments, views)
这时再查,結果以下:

应用了key字段名表明应用了联合索引idx_article_ccv,type表明浏览种类是一个range按范畴查看。可是還是应用了文件排序(using filesort)
缘故是应用了范畴标准(comments>1)以后的标准或排列没法应用数据库索引,换句话说 views 字段名排列没用到数据库索引。
提升2:删除刚的数据库索引,再次建立联合索引 index idx_article_ccv (category_id, views)
这一数据库索引只包括2个字段名,没有comments字段名。

Type的种类是ref,应用到数据库索引,并且沒有采用文件排序,只是应用了数据库索引B 树中的排列。
mysql会寻找B 树中考虑category_id=1的叶子节点(包括别的列数据信息),从硬盘载入到运行内存,随后再在运行内存中过虑寻找comments>1的数据信息。因为在B 树中早已排好啦序因此 不容易在运行内存中对views排列。
2.如今有一个blog表(也是一个文章内容表)blogs,还有一个归类表 category 。想做一个关联查询,关系字段名是category.id = blogs.tid。假定如今category.id是主键,可是blogs.tid沒有创建数据库索引。
explain select * from blogs b join category c on b.tid=c.id;
結果以下:
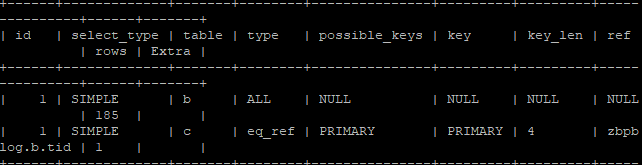
发觉blogs表全表扫描仪(type为All),沒有采用数据库索引(key为null),扫描仪总数为185(我的网站表一共仅有185条纪录);而category是唯一索引扫描仪(type为eq_ref),应用了主键(key为primary),只扫描仪了1条(category表共10个归类,有10条纪录)
blog表是一个全表扫描仪,高效率很低。
提升1:对blogs的tid创建列项数据库索引后再查

发觉如今变为 category沒有应用数据库索引,而blogs应用了数据库索引tid,浏览种类是ref。扫描仪的总数变成 10 23 = 33。高效率明显增强。
这一事例想表明的是:
A.inner join联查,mysql默认设置小表做为驱动器表,大表做为被驱动器表,让小表驱动器大表。
Left join联查,mysql会让左侧的表做为驱动器表,右侧的表做为被驱动器表。Right join同样。
B.多表联查会全表扫描驱动表的(事例中的表category),因此 在应用left join的情况下尽可能把小表放到左侧,让小表变成驱动器表,那样会对小表开展全表扫描仪,好以往对大表全表扫描仪。
C.多表联查时要确保关系字段名创建了数据库索引
